Editorial
Date
Partner(s)

This article presents a study conducted in 2023 by the CDRIN team in collaboration with Squido Studio, examining the use of AI for 3D object creation in independent game studios. Squido enlisted CDRIN's expertise to explore an innovative text-to-2D-to-3D method. While the original approach utilizes Stable Diffusion to generate 2D images and DreamGaussian for 3D transformation, significant technological advancements have since emerged. Recent models like Stable Fast 3D and enhanced transformer networks have addressed many of the initial quality challenges. The study thus highlights the rapid evolution of AI technologies for 3D artist tools in the independent game industry, demonstrating both the initial limitations and the promising potential of AI-driven 3D object generation.
These days, we constantly hear about new things that AI can do, impressive demos are everywhere, numerous use cases, research papers are emerging from all directions daily, etc. However, upon closer inspection, there are not that many real products out there that complete the entire process and even partially, but with a quality level that can be considered production-ready.
Our Mission: Making AI Accessible
We are a research center working on projects in the gaming and entertainment sector. Each new AI model in this domain is presented as if it will replace a significant portion of the workforce, eliminate creativity, creates fear within the artistic community, but in reality, most of the time these tools are neither ready nor artist-friendly enough to be used and create something meaningful other than just being a fun demo to show to your friends (assuming you still have friends 😀).
Nevertheless, we understand that the potential is huge and especially for small game studios, because it can level the playing field and they can have a chance to compete with bigger studios. Democratizing these tools among small Canadian studios is well aligned with our mission and we are always ready to help given the opportunity.
The Squido Studio Challenge: 3D Asset Generation
An opportunity for collaboration was presented by David Chartrand, the CEO of Squido Studio. As many small studios, they too, lack substantial resources to scale fast enough, so naturally they think AI can help. They are building VR games and they need a big quantity of 3D objects/assets that follow the same artistic style and direction. Our goal was to generate those 3D objects based on the textual description, aka prompting. However, it’s not prompt engineering, but to suggest a production pipeline and test all the steps. This presented an intriguing challenge, which we eagerly accepted!
Our Approach: A Two-Step Pipeline
After some literature review on direct text-to-3D approaches (we will briefly cover this later in the article) we concluded that the results are not very promising, however there are many good text-to-image and image-to-3D AI models that we can test out. Consequently, we proposed a two step pipeline for generating 3D objects from text by passing via 2D image step first.
Furthermore, text-to-image generation is so much more advanced than generating 3D objects, that there are already many tools and controls available such as Automatic1111 for web interface, all local and open source using Stable Diffusion (SD) models and ControlNets on top of them in order to manipulate the generated results with many different ways.
Stable Diffusion & ControlNets: Our Core Tools
One specific control method they emphasized was the capability to generate 2D images based on the sketches such as these ones:

The generated image should then be used to create 3D objects. This seems like a straightforward and comprehensible task, but let’s examine how it actually works.
Fine-Tuning for Style
We began by comparing SD models with other image generators such as CM3leon, Midjourney and Dall·E. Each has its advantages, but we choose SD for our project for several reasons:
- Flexibility: You can train (fine-tune) your own models on your own data.
- Reliability: You don’t depend on an internet connection or third-party servers being operational during critical work periods.
- Speed: It’s usually faster to generate images and iterate on a local machine.
- Data privacy: You may not want your assets created on online platforms.
The first point is very critical for the project, as we want to retrain (or fine-tune) the model to reflect Squido’s art style. There are many ways to perform fine-tuning, but for our purposes, we used a paper called DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. Without further ado, here are some results of transforming sketches into 2D images in Squido’s style:


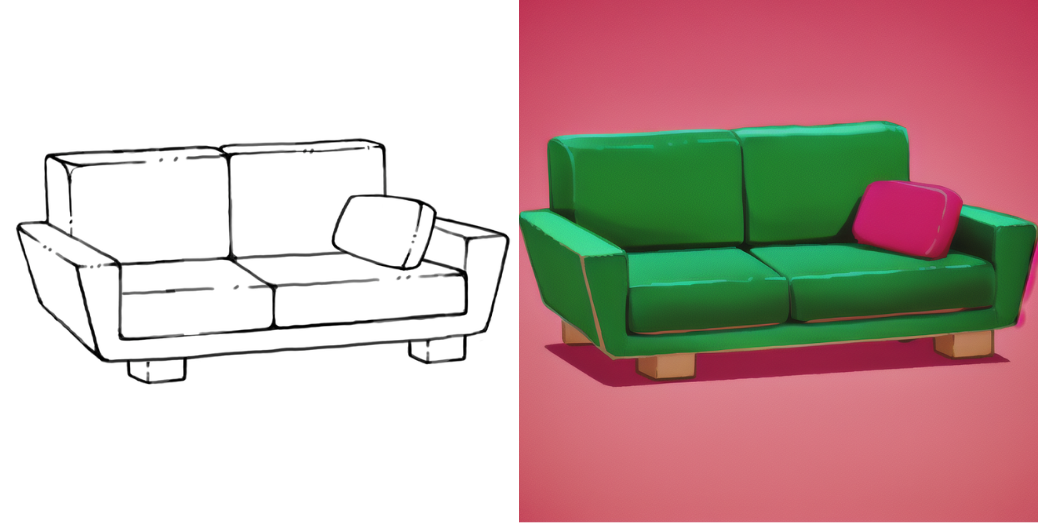
It looks like this first part of the pipeline is coming together nicely. Let’s see what we have on generating 3D objects from these images.
3D Generation: A Significant Hurdle
Training 3D object generator AI models is particularly challenging because there’s far less 3D data available than 2D data. At the same time, image generation models have improved, now producing high-fidelity and diverse images thanks to large image-text datasets and scalable architecturees.
DreamGaussian: Improving 3D Generation
The rise of NeRFs and image diffusion models led to an important early work, and by early I mean 2022, DreamFusion, which first introduced a popular method called Score Distillation Sampling (SDS). DreamFusion demonstrated that it is possible to generate 3D objects using only 2D priors, i.e., distilling large pre-trained text-to-image diffusion models.
Later, other researchers attempted to further improve this, aiming for higher resolution and better quality results, and faster generation. For example, DreamGaussian, one of the methods we explored in this project, leverages Gaussian Splatting for 3D representation instead of NeRFs, resulting in much faster performance.
The Limits of Text-to-3D Models
A common problem in text-to-3D generation is the Janus or Multi-Face problem, which refers to a lack of consistency across views when using only 2D priors. To address this issue, some methods have combined 2D and 3D priors. One way to incorporate 3D data is the use of view-conditioned image generation, where 3D objects are rendered with different camera angles and are used to train a 2D diffusion model to predict novel views given an input image. Along with the RGB images, you can render geometric details such as surface normal maps. Stable Zero123, Zero123-XL, MVDream, and Wonder3D are examples of view-conditioned image generation models.
Finally, these models often generate representations such as NeRF or Gaussian Splatting. However, 3D meshes are still the main representation used in most Computer Graphics pipelines (e.g., game engines). Algorithms such as Marching Cubes and DMTet are commonly used to extract the meshes.
As mentioned earlier, we’ve opted for a two-step approach to 3D object generation: first text-to-2D, then 2D-to-3D. Most text-to-3D models such as DreamFusion, use text prompts to condition the diffusion model in the SDS updates. However, text descriptions can be ambiguous or lack detail. Using text-to-2D models like Stable Diffusion offers more control over the generated results by allowing us to fine-tune the text-to-2D model on our own data and to achieve our desired style. Starting with an image provides a clear visual reference, which helps the AI create 3D objects that more closely align with our vision.
Testing the Models: Results and Challenges
Now let’s evaluate these models on the images generated from the initial sketches using Stable Diffusion, in the style of Squido. We tried different models such as DreamGaussian (Zero123-xl, Stable-zero123), Wonder3D, ShapeE, and One-2-3-45. Based on our tests during this project, DreamGaussian consistently delivered the best results overall, with Wonder3D coming in as the second best.

Based on our observations, currently generated meshes all share the following problems:
- Too many polygons for a video game (high polycount)
- Problematic topology (floating and/or overlapping vertices, complex collision)
- Inaccurate shapes (bumpy surfaces with holes)

Improvements and Limitations
We tried to enhance the quality of the generated meshes by tweaking model parameters and applying post-processing techniques like remeshing or mesh decimation. However, it seems that manually adjusting the generated meshes would take even more time than creating them from scratch. Now, let’s look at some of the best and worst results:

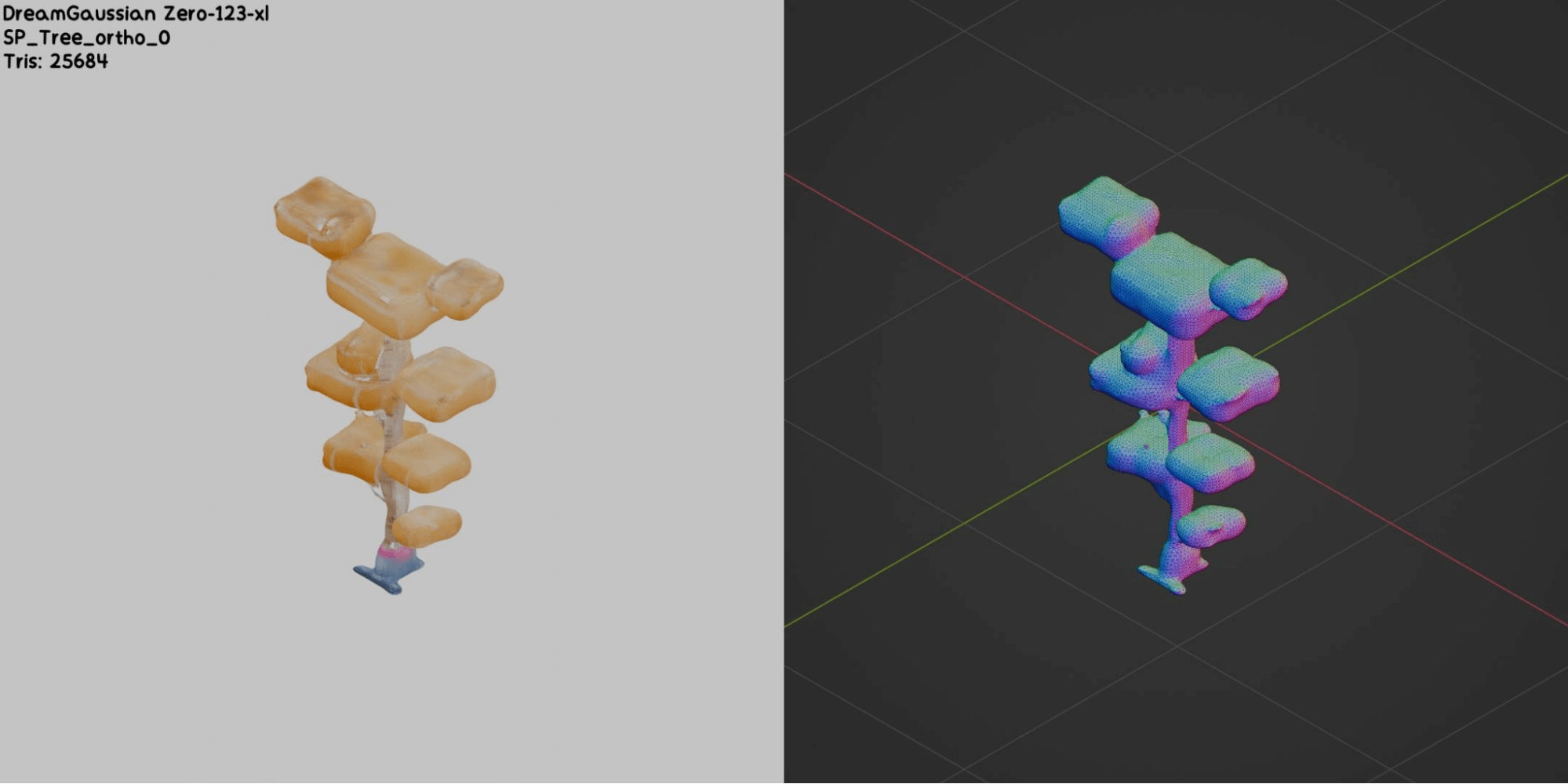
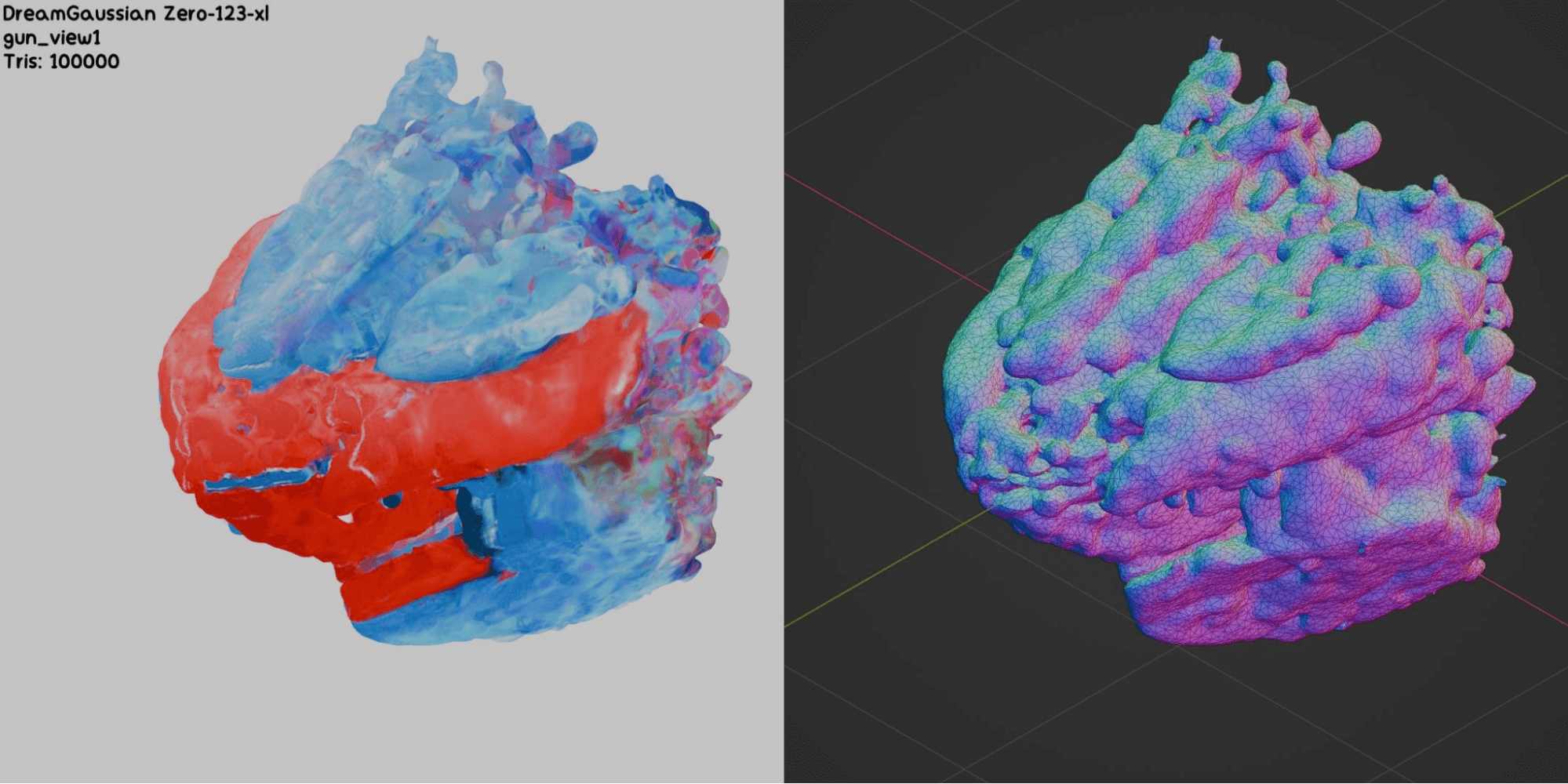
Our Attempts to Optimize Meshes
Given the current challenges and significant room for improvement with AI-generated 3D objects and building on our colleague Azzahrae El-Khiati’s findings for another project in 3D generation models (we will share about that one very soon), we recommend focusing future research on the key areas of development:
- 3D Generation Models Enhancement: While DreamGaussian has shown promising results, it is crucial to continue exploring and enhancing 3D generation models. Research should focus on models that can produce meshes with cleaner topology and lower polygon counts, suitable for video game production. Recent models like Stable Fast 3D, which generate more consistent results, warrant further investigation.
- 3D Data Integration and Representation: To address view inconsistency issues related to using only 2D priors, it’s important to incorporate 3D data during object generation. The use of view-conditioned image generation models, which use images of 3D objects from different angles, could improve the quality of generated objects.
- Mesh Optimization: Since manual adjustments are time-consuming, it’s important to explore automatic post-processing techniques for meshes, such as remeshing and decimation. These techniques could reduce polygon counts and improve topology without excessive manual intervention.
- 3D Artist-Centric Tools: Rather than seeking to replace 3D artists, the focus could be on developing AI-powered tools to assist them in their work. These tools could include functions for mesh generation, optimization, and modification, with an intuitive interface for artists.
- Real-World Validation: It’s important to validate models and techniques developed in real-world use cases. This will help to better understand the limits and strengths of different approaches and tailor them to the real needs of video game production.
- Iterative Development: An iterative approach is crucial. This means testing different methods, analyzing their performance, and readjusting based on the results. Furthermore, close collaboration between researchers and 3D artists is necessary to better understand the technical needs and constraints.
The Artist’s Perspective: AI in the Creative Process
While we have explored the possibilities offered by AI for generating 3D objects, it seems essential to consider the perspective of an artist who works directly with these tools. Christophe Marois, our technical artist, shares his experience and reflections on the relevance and challenges of AI in his creative process.
As mentioned above, in our tests, the AI-generated objects looked strange and were not ready for use. As an artist, I’d rather start from scratch than have to clean up a problematic object first.
However, the objects can be optimized to a point where only their appearance matters. They would still look odd and be hard to modify, but could technically be supported in a video game.
Since the optimization can be done automatically with clever algorithms, one could make a video game where players “create” objects by describing them. The objects won’t look great, but with some creative effects they might be acceptable.
I find it impressive that artificial intelligence can mimic the work of a 3D artist. However, I would be more excited to see great tools that help 3D artists create good models instead. If you like to cook, would you rather have a bland version of your meal prepared for you, or make it yourself with an amazing kitchen and all the tools you need?

Where Do We Go From Here?
While initial experiments with AI-generated 3D objects showed limitations, the field is rapidly evolving. As AI continues to develop, more practical and effective tools are expected. This swift technological evolution could revolutionize 3D asset creation for independent game studios.
The above experiments were conducted a year ago, and much has changed since then. Recent models leverage transformer architecture for fast feed-forward 3D generation. LRM and TripoSR are examples of transformer-based 3D generation models.
Recently, SPAR3D (an improved version of Stable Fast 3D) was released by Stability AI, which seems to generate much more consistent results. Another example is TRELLIS, a model developed by Microsoft that enables high-quality 3D content creation (see GitHub and Trellis 3d’s official page). We have seen quite a few new models emerging recently, but these are just two noteworthy examples.

