Rédaction
Date
Partenaire(s)

Cet article présente une étude menée en 2023-2024 par l'équipe du CDRIN en collaboration avec Squido Studio, examinant l'utilisation de l'IA pour la création d'objets 3D dans les studios de jeux indépendants. Squido a sollicité l'expertise du CDRIN pour explorer une méthode innovante de conversion texte 2D en 3D. L'approche initiale repose sur l'utilisation de Stable Diffusion pour générer des images 2D et de DreamGaussian pour la transformation en 3D. Cependant, d'importantes avancées technologiques ont émergé depuis. Des modèles récents comme Stable Fast 3D et des réseaux de transformeurs améliorés ont résolu de nombreux défis de qualité initiaux. L'étude met ainsi en lumière l'évolution rapide des technologies d'IA destinées aux outils des artistes 3D dans l'industrie du jeu indépendant, démontrant à la fois les limites initiales et le potentiel prometteur de la génération d'objets 3D par IA.
De nos jours, nous entendons constamment parler de nouvelles choses que l’IA peut faire, des démonstrations impressionnantes sont partout, de nombreux cas d’utilisation, des articles de recherche émergent quotidiennement de toutes les directions, etc. Cependant, après un examen plus approfondi, il n’y a pas beaucoup de vrais produits qui complètent l’ensemble du processus, même partiellement, mais avec un niveau de qualité qui peut être considéré prêt pour la production.
Notre mission : Rendre l’IA accessible
Nous sommes un centre de recherche travaillant sur des projets dans le secteur du jeu et du divertissement. Chaque nouveau modèle d’IA dans ce domaine est présenté comme s’il allait remplacer une partie importante de la main-d’œuvre, éliminer la créativité, créer la peur au sein de la communauté artistique, mais en réalité, la plupart du temps, ces outils ne sont ni prêts ni suffisamment conviviaux pour être utilisés et créer quelque chose de significatif, à part être une démo amusante à montrer à vos amis (en supposant que vous ayez encore des amis 😀).
Néanmoins, nous comprenons que le potentiel est énorme, en particulier pour les petits studios de jeux, car cela peut aider à équilibrer les chances et leur donner une chance de rivaliser avec les plus grands studios. Démocratiser ces outils auprès des petits studios canadiens correspond bien à notre mission et nous sommes toujours prêts à aider si l’occasion se présente.
Le défi de Squido Studio: Génération d’assets 3D
Une opportunité de collaboration a été présentée par David Chartrand, le PDG de Squido Studio. Comme de nombreux petits studios, ils manquent également de ressources importantes pour évoluer assez rapidement, il est donc naturel qu’ils pensent que l’IA peut aider. Ils construisent des jeux VR et ils ont besoin d’une grande quantité d’objets/assets 3D qui suivent le même style et la même direction artistique. Notre objectif était de générer ces objets 3D à partir de la description textuelle, alias prompting. Cependant, il ne s’agit pas d’ingénierie de prompts, mais de suggérer un pipeline de production et de tester toutes les étapes. Cela a présenté un défi intéressant, que nous avons accepté avec enthousiasme!
Notre approche : Un pipeline en deux étapes
Après une revue de la littérature sur les approches directes text-to-3D (nous aborderons brièvement ce sujet plus loin dans l’article), nous avons conclu que les résultats ne sont pas très prometteurs, mais il existe de nombreux bons modèles d’IA text-to-image et image-to-3D que nous pouvons tester. Par conséquent, nous avons proposé un pipeline en deux étapes pour générer des objets 3D à partir de texte en passant d’abord par l’étape d’image 2D.
De plus, la génération text-to-image est tellement plus avancée que la génération d’objets 3D, qu’il existe déjà de nombreux outils et contrôles disponibles tels que Automatic1111 pour l’interface web, tous locaux et open source utilisant les modèles Stable Diffusion (SD) et les ControlNets par-dessus afin de manipuler les résultats générés de nombreuses manières différentes.
Stable Diffusion & ControlNets: Nos outils principaux
Une méthode de contrôle spécifique qu’ils ont soulignée était la capacité de générer des images 2D basées sur les croquis tels que ceux-ci:

L’image générée doit ensuite être utilisée pour créer des objets 3D. Cela semble être une tâche simple et compréhensible, mais examinons comment cela fonctionne réellement.
Fine-Tuning pour le style
Nous avons commencé par comparer les modèles SD avec d’autres générateurs d’images tels que CM3leon, Midjourney et Dall·E. Chacun a ses avantages, mais nous avons choisi SD pour notre projet pour plusieurs raisons:
- Flexibilité: Vous pouvez entraîner (fine-tune) vos propres modèles sur vos propres données.
- Fiabilité: Vous ne dépendez pas d’une connexion Internet ou du fonctionnement de serveurs tiers pendant les périodes de travail critiques.
- Vitesse: Il est généralement plus rapide de générer des images et d’itérer sur une machine locale.
- Confidentialité des données: Vous ne voulez peut-être pas que vos assets soient créés sur des plateformes en ligne.
Le premier point est très important pour le projet, car nous voulons réentraîner (ou fine-tune) le modèle pour refléter le style artistique de Squido. Il existe de nombreuses façons d’effectuer le fine-tuning, mais pour nos besoins, nous avons utilisé un article intitulé DreamBooth : Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. Sans plus tarder, voici quelques résultats de la transformation d’esquisses en images 2D dans le style de Squido:


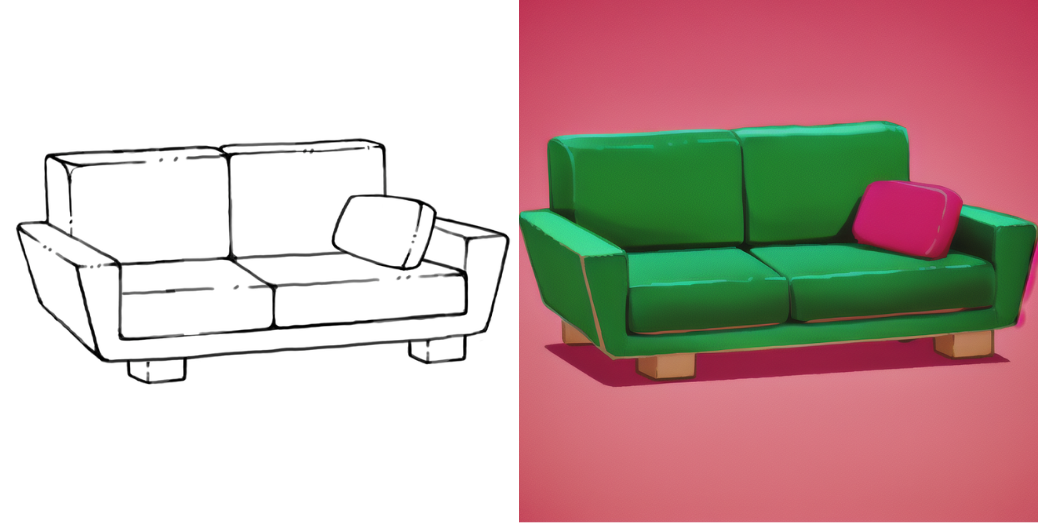
Il semble que cette première partie du pipeline se met en place très bien. Voyons ce que nous avons sur la génération d’objets 3D à partir de ces images.
Génération 3D: Un obstacle important
L’entraînement des modèles d’IA de génération d’objets 3D est particulièrement difficile car il y a beaucoup moins de données 3D disponibles que de données 2D. Parallèlement, les modèles de génération d’images se sont améliorés, produisant désormais des images haute fidélité et diverses grâce à de vastes ensembles de données image-texte et à des architectures évolutives.
DreamGaussian: Améliorer la génération 3D
L’essor des NeRF et des modèles de diffusion d’images a conduit à un premier travail important, et par premier, je veux dire 2022, DreamFusion, qui a d’abord introduit une méthode populaire appelée Score Distillation Sampling (SDS). DreamFusion a démontré qu’il est possible de générer des objets 3D en utilisant uniquement des priors 2D, c’est-à-dire en distillant de grands modèles de diffusion text-to-image pré-entraînés.
Plus tard, d’autres chercheurs ont tenté d’améliorer cela davantage, en visant une résolution plus élevée et des résultats de meilleure qualité, et une génération plus rapide. Par exemple, DreamGaussian, l’une des méthodes que nous avons explorées dans ce projet, exploite Gaussian Splatting pour la représentation 3D au lieu des NeRF, ce qui se traduit par des performances beaucoup plus rapides.
Les limites des modèles Text-to-3D
Un problème courant dans la génération text-to-3D est le problème Janus ou Multi-Face, qui fait référence à un manque de cohérence entre les vues lorsque l’on utilise uniquement des priors 2D. Pour résoudre ce problème, certaines méthodes ont combiné des priors 2D et 3D. Une façon d’incorporer des données 3D est l’utilisation de la génération d’images conditionnée par la vue, où les objets 3D sont rendus avec différents angles de caméra et sont utilisés pour entraîner un modèle de diffusion 2D afin de prédire de nouvelles vues étant donné une image d’entrée. Parallèlement aux images RVB, vous pouvez rendre des détails géométriques tels que des normal maps de surface. Stable Zero123, Zero123-XL, MVDream et Wonder3D sont des exemples de modèles de génération d’images conditionnés par la vue.
Enfin, ces modèles génèrent souvent des représentations telles que NeRF ou Gaussian Splatting. Cependant, les 3D mesh sont toujours la principale représentation utilisée dans la plupart des pipelines d’infographie (par exemple, les moteurs de jeux). Les algorithmes tels que Marching Cubes et DMTet sont couramment utilisés pour extraire les meshes.
Comme mentionné précédemment, nous avons opté pour une approche en deux étapes de la génération d’objets 3D : d’abord text-to-2D, puis 2D-to-3D. La plupart des modèles text-to-3D tels que DreamFusion, utilisent des prompts textuels pour conditionner le modèle de diffusion dans les mises à jour SDS. Cependant, les descriptions textuelles peuvent être ambiguës ou manquer de détails. L’utilisation de modèles text-to-2D comme Stable Diffusion offre plus de contrôle sur les résultats générés en nous permettant de fine-tune le modèle text-to-2D sur nos propres données et d’obtenir le style souhaité. Commencer par une image fournit une référence visuelle claire, ce qui aide l’IA à créer des objets 3D qui correspondent plus étroitement à notre vision.
Test des modèles : Résultats et défis
Maintenant, évaluons ces modèles sur les images générées à partir des croquis initiaux en utilisant Stable Diffusion, dans le style de Squido. Nous avons essayé différents modèles tels que DreamGaussian (Zero123-xl, Stable-zero123), Wonder3D, ShapeE et One-2-3-45. D’après nos tests au cours de ce projet, DreamGaussian a constamment fourni les meilleurs résultats globaux, Wonder3D arrivant en deuxième position.

D’après nos observations, les meshes générés actuellement partagent tous les problèmes suivants:
- Trop de polygones pour un jeu vidéo (nombre élevé de polygones)
- Topologie problématique (sommets flottants et/ou se chevauchant, collision complexe)
- Formes inexactes (surfaces bosselées avec des trous)

Améliorations et limitations
Nous avons essayé d’améliorer la qualité des meshes générés en modifiant les paramètres du modèle et en appliquant des techniques de post-traitement comme le remeshing ou la décimation de meshes. Cependant, il semble que l’ajustement manuel des meshes générés prendrait encore plus de temps que de les créer à partir de zéro. Maintenant, regardons quelques-uns des meilleurs et des pires résultats:

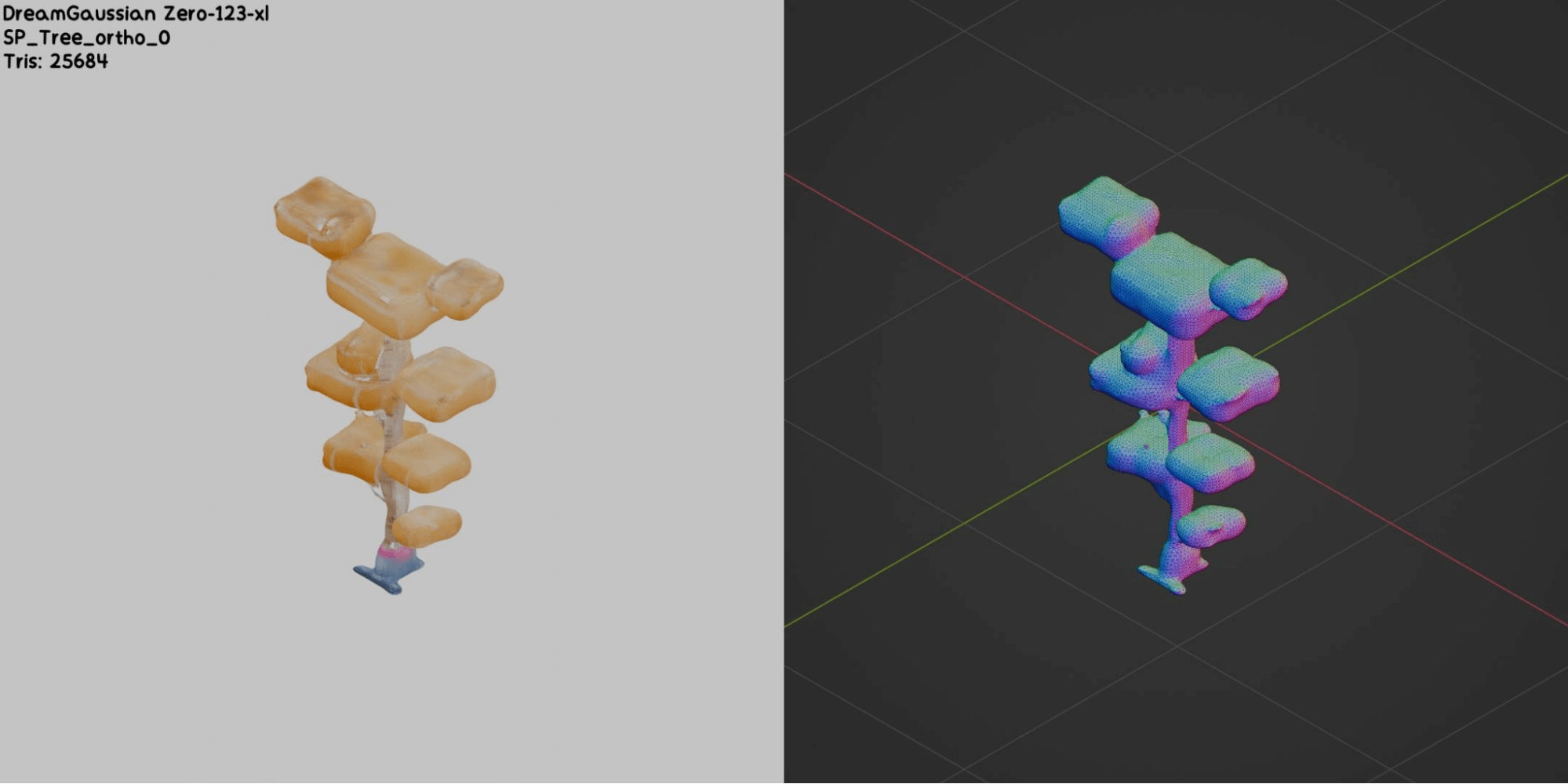
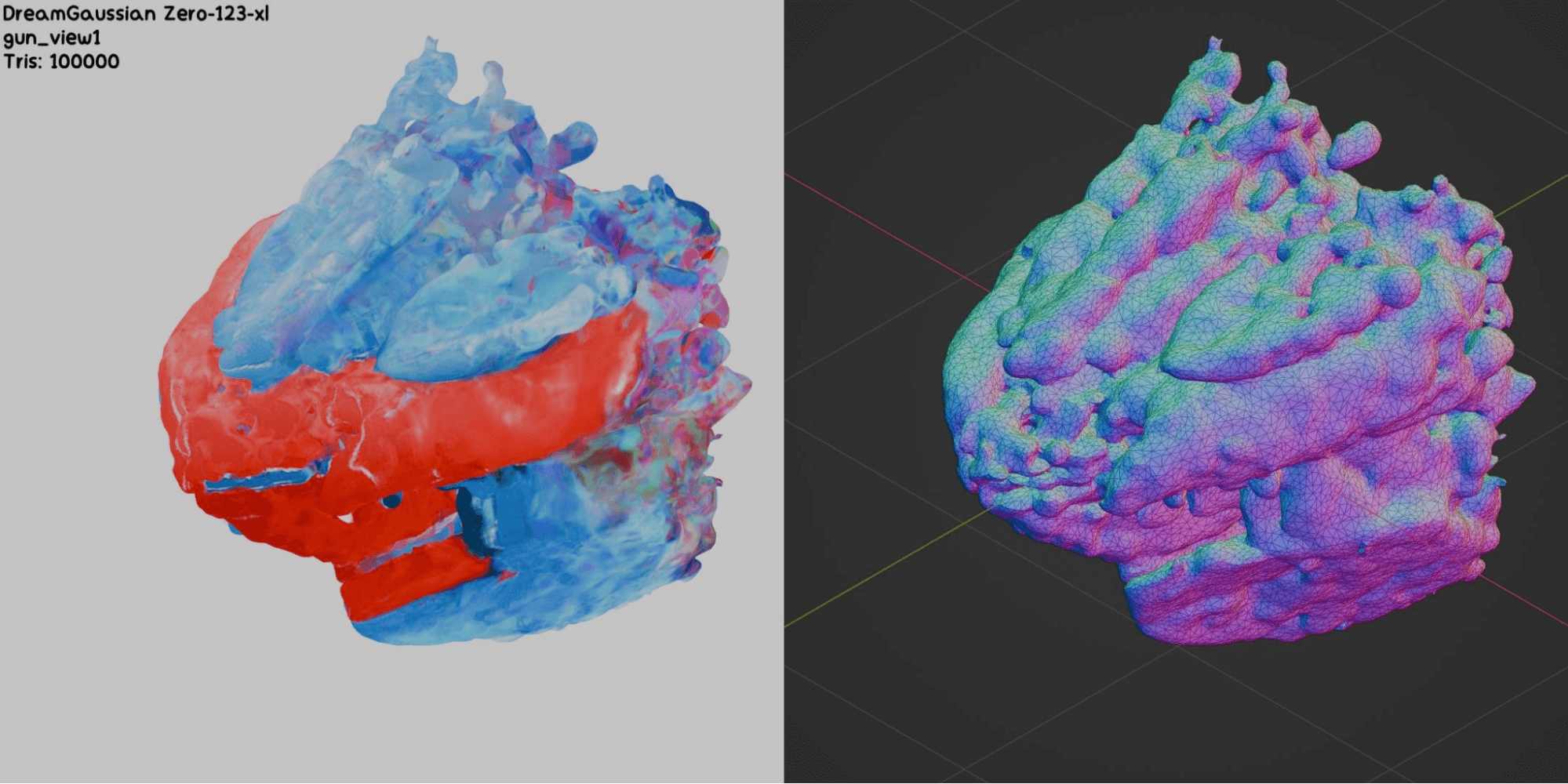
Nos tentatives d’optimisation des meshes
Compte tenu des défis actuels et de la marge d’amélioration significative avec les objets 3D générés par l’IA et en nous appuyant sur les conclusions de notre collègue chercheure-programmeuse Azzahrae El-Khiati pour un autre projet sur les modèles de génération 3D (nous partagerons bientôt des informations à ce sujet), nous recommandons de concentrer les recherches futures sur les principaux domaines de développement:
- Amélioration des modèles de génération 3D: Bien que DreamGaussian ait montré des résultats prometteurs, il est essentiel de continuer à explorer et à améliorer les modèles de génération 3D. La recherche devrait se concentrer sur les modèles capables de produire des meshes avec une topologie plus propre et un nombre de polygones plus faible, adaptés à la production de jeux vidéo. Les modèles récents comme Stable Fast 3D, qui génèrent des résultats plus cohérents, méritent une enquête plus approfondie.
- Intégration et représentation des données 3D: Pour résoudre les problèmes d’incohérence de vue liés à l’utilisation de priors 2D uniquement, il est important d’intégrer des données 3D lors de la génération d’objets. L’utilisation de modèles de génération d’images conditionnés par la vue, qui utilisent des images d’objets 3D sous différents angles, pourrait améliorer la qualité des objets générés.
- Optimisation des meshes: Étant donné que les ajustements manuels prennent du temps, il est important d’explorer des techniques de post-traitement automatiques pour les meshes, telles que le remeshing et la décimation. Ces techniques pourraient réduire le nombre de polygones et améliorer la topologie sans intervention manuelle excessive.
- Outils centrés sur les artistes 3D: Plutôt que de chercher à remplacer les artistes 3D, l’accent pourrait être mis sur le développement d’outils basés sur l’IA pour les aider dans leur travail. Ces outils pourraient inclure des fonctions de génération, d’optimisation et de modification de meshes, avec une interface intuitive pour les artistes.
- Validation dans le monde réel: Il est important de valider les modèles et les techniques développés dans des cas d’utilisation réels. Cela aidera à mieux comprendre les limites et les forces des différentes approches et à les adapter aux besoins réels de la production de jeux vidéo.
- Développement itératif: Une approche itérative est cruciale. Cela signifie tester différentes méthodes, analyser leurs performances et se réajuster en fonction des résultats. De plus, une collaboration étroite entre les chercheurs et les artistes 3D est nécessaire pour mieux comprendre les besoins et les contraintes techniques.
Le point de vue de l’artiste : L’IA dans le processus créatif
Bien que nous ayons exploré les possibilités offertes par l’IA pour la génération d’objets 3D, il semble essentiel de considérer le point de vue d’un artiste qui travaille directement avec ces outils. Christophe Marois, notre artiste technique, partage son expérience et ses réflexions sur la pertinence et les défis de l’IA dans son processus créatif.
Comme mentionné ci-dessus, lors de nos tests, les objets générés par l’IA avaient l’air étranges et n’étaient pas prêts à être utilisés. En tant qu’artiste, je préférerais repartir de zéro plutôt que d’avoir à nettoyer d’abord un objet problématique.
Cependant, les objets peuvent être optimisés au point où seule leur apparence compte. Ils auraient toujours l’air étranges et seraient difficiles à modifier, mais pourraient techniquement être pris en charge dans un jeu vidéo.
Étant donné que l’optimisation peut être effectuée automatiquement avec des algorithmes intelligents, on pourrait créer un jeu vidéo où les joueurs et joueuses «créent» des objets en les décrivant. Les objets n’auront pas belle allure, mais avec des effets créatifs, ils pourraient être acceptables.
Je trouve impressionnant que l’intelligence artificielle puisse imiter le travail d’un artiste 3D. Cependant, je serais plus enthousiasmé de voir d’excellents outils qui aident les artistes 3D à créer de bons modèles à la place. Si vous aimez cuisiner, préféreriez-vous qu’une version fade de votre repas soit préparée pour vous, ou la préparer vous-même avec une cuisine incroyable et tous les outils dont vous avez besoin?

Où allons-nous à partir d’ici?
Bien que les premières expériences avec les objets 3D générés par l’IA aient montré des limites, le domaine évolue rapidement. Au fur et à mesure que l’IA continue de se développer, des outils plus pratiques et efficaces sont attendus. Cette évolution technologique rapide pourrait révolutionner la création d’assets 3D pour les studios de jeux indépendants.
Les expériences ci-dessus ont été menées il y a un an, et beaucoup de choses ont changé depuis lors. Les modèles récents exploitent l’architecture de transformateur pour une génération 3D rapide à alimentation directe. LRM et TripoSR sont des exemples de modèles de génération 3D basés sur des transformateurs.
Récemment, SPAR3D (une version améliorée de Stable Fast 3D) a été publié par Stability AI, qui semble générer des résultats beaucoup plus cohérents. Un autre exemple est TRELLIS, un modèle développé par Microsoft qui permet la création de contenu 3D de haute qualité (voir GitHub et la page officielle de Trellis 3d). Nous avons vu pas mal de nouveaux modèles émerger récemment, mais ce ne sont que deux exemples notables.

